<AI開発 part 1>日本人のタレントの顔画像と年齢のデータを集める
日本人のタレントの顔画像と年齢のデータを集めるスクレイピングに挑戦した
<追記>
著作権については、研究開発目的であり、許諾なしで利用可能である。 詳しくはリンクで確認してほしい。(https://storialaw.jp/blog/4936) やっぱ、日本はこういうところが最高やな!
日本人の顔画像は超貴重
まず、日本人の顔画像のデータセット(性別、年齢、顔画像がそろっているもの)はGoogleで検索しても出てこない。
日本人は世界で数少ない人種だけにデータセットが少ないのだ。
経緯
すでにいくつかの記事で話しているが、私はロボカッププロジェクトに参加している。
その際に、画像から年齢、性別を読み取り、人間と対話するタスクがある。
したがって、画像から年齢、性別を推論するAI(ディープラーニング)が必要になった。 AIに学習させるにはデータが大量に必要だが、肝心の日本人のデータがないのでは、困る。
そこで、タレント図鑑 というサイトを発見した。このサイトでは、日本人のタレントを年齢、顔画像とともに公開している。
いざダウンロード。
本来、このサイトからダウンロードするには、一つ一つ右クリックしてダウンロードしていくほかないのだが、スクレイピングという、簡単なプログラムでその保存作業を自動化できるので、それに挑戦した。
コードは短いが、使ったことのないライブラリだったので、苦戦したが、何とか動いた。
import urllib.request
import time,os
get_photo_ages=list(range(5,80))
SAVEPATH=r"photos"
URL="https://www.talent-databank.co.jp"
def init():
os.makedirs(SAVEPATH,exist_ok=True)
from selenium import webdriver
options = webdriver.ChromeOptions()
# options.add_argument('--headless')
driver = webdriver.Chrome(options=options) # 今は chrome_options= ではなく options=
driver.get(URL)
print(driver.title)
driver.find_element_by_xpath("/html/body/div[1]/div/div[3]/div[1]/div[1]/div[1]/form/div/p/input[2]").click()
print("init end")
time.sleep(2)
return driver
def main():
driver=init()
for age in get_photo_ages:
# 検索 入力
min_age=driver.find_element_by_name("age_min")
min_age.clear()
min_age.send_keys(str(age))
max_age=driver.find_element_by_name("age_max")
max_age.clear()
max_age.send_keys(str(age))
driver.find_element_by_xpath("/html/body/div[1]/div/div[3]/div[1]/div/form/div[3]/div/span/input").click()
save_count=1
failcount=0
now_page=1
print("now age===>%d"%age,end="")
while True:
# <tr> 抜き出し
element=driver.find_elements_by_tag_name("tr")[1::]
for ele in element:
# <a> save
try:
photo=ele.find_element_by_tag_name("img").get_attribute("src")
p=os.path.join(SAVEPATH,f"{age}_{save_count}.jpg")
# print(p)
urllib.request.urlretrieve(photo,p)
except:
failcount+=1
print("fail")
save_count+=1
try:
nextpage=driver.find_elements_by_xpath("//a[contains(text(),'次のページ')]")[0]
nextpage.click()
now_page+=1
except:
break
finally:
print("page%d saved==>%d"%(now_page,save_count-failcount))
time.sleep(1.0)
if __name__ == "__main__":
main()
多少強引な書き方をしているが、動けばいい。
なお、このコードを動かす際は
>> pip3 install selenium chromedriver-binary
が必要だ。
結論
得られたデータは約1.7万枚であり、解像度:200x200、サイズ:42.7KBであった。
ただし、年齢によって、枚数に偏りがあるため、枚数を調整する必要がある。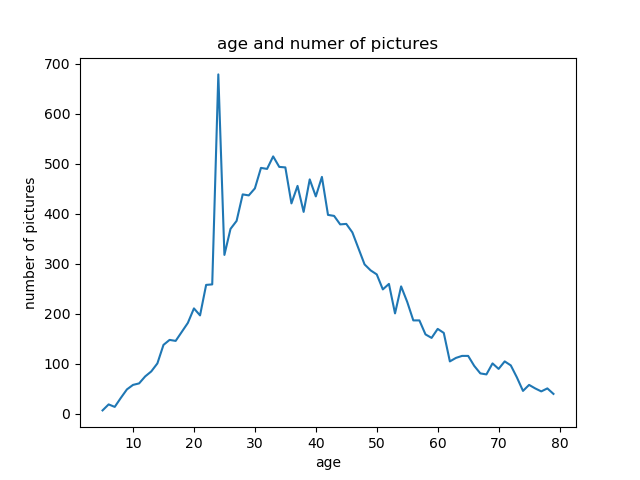 ここから、年齢回帰と性別分類を行う予定である。
ここから、年齢回帰と性別分類を行う予定である。